

Wie schon im Blogartikel "Was ist ein Translation Memory" aufgezeigt, verstehen wir unter einem Translation Memory (kurz TM) eine Datenbank, in der Übersetzungen in Form von einzelnen Segmenten gespeichert werden. Angeknüpft an eine Translation Software schlägt das Translation Memory bei neuen Übersetzungen sogenannte Matches vor. In diesem Beitrag möchten wir Ihnen zeigen, wie ein Translation Memory System funktioniert und was es mit den Matches auf sich hat. Dazu haben wir hier ein paar spannende Informationen zum Thema zusammengetragen.
Inhaltsverzeichnis
Die Matchraten
Als "Matches" oder auch "Treffer" bezeichnen wir vereinfacht gesagt Übereinstimmungen zwischen dem Translation Memory und dem neu zu übersetzenden Text. Wenn eine Ähnlichkeit zu den Segmenten im TM besteht, ordnet das System die Übereinstimmungen je nach Ähnlichkeitsgrad bestimmten Kategorien bzw. Matchraten zu. Diese Matchraten wollen wir uns nun etwas näher ansehen.
Wenn Sie eine neue Übersetzung in Auftrag geben, bereiten wir die Dokumente für die Übersetzenden vor und binden auch die jeweiligen Translation Memorys in das Übersetzungsprojekt ein. Übereinstimmungen zwischen dem Translation Memory und dem zu übersetzenden Text zeigt das System in Prozentwerten an. Diese Matches fasst das Translation Memory System automatisch in folgende Kategorien zusammen:
- Context Matches (kurz auch CM)
- Wiederholungen
- 100% Matches
- 95%-99% Matches
- 85%-94% Matches
- 75%-85% Matches
- 50%-74% Matches
- Neutext (= no match)
Wenn das System in dem zu übersetzenden Text ein Segment findet, das 1:1 mit einem Segment im Translation Memory übereinstimmt, dann wird es als 100% Match definiert. Die Übereinstimmung bezieht sich aber nicht nur auf den Text selbst; die Formatierung muss ebenfalls komplett übereinstimmen. Findet das Translation Memory sowohl im vorhergehenden als auch im nachfolgenden Segment ein 100% Match, dann bezeichnen wir dieses als sogenanntes Context Match.
Alle anderen Segmente, deren Ähnlichkeitswert unter 100% liegt, nennen wir "Fuzzy" Matches. Für diese Segmente erhalten die Übersetzenden schon Vorschläge aus dem Translation Memory, sie müssen jedoch noch – je nach Ähnlichkeitsgrad – kleine Anpassungen durchführen. Wenn es kein Match aus dem Translation Memory gibt, klassifiziert das System die betroffenen Segmente als Neutext bzw. "no match".
Die richtige Segmentierung
Der wichtigste Ausgangspunkt, um gut mit einem Translation Memory arbeiten zu können, ist die richtige Segmentierung oder Aufteilung des Textes in komplette Sätze. Besonders bei nicht editierbaren Formaten passiert es häufig, dass das System den Text nicht sauber ausliest. Textteile, die eigentlich zusammengehören, scheinen dann in unterschiedlichen Segmenten auf, anstatt eine Einheit zu bilden. Das führt dazu, dass das Translation Memory keine oder nur sehr niedrige Trefferwerte für diese Segmente anzeigt, obwohl der komplette Text eigentlich im Translation Memory vorhanden ist.
Sehen wir uns dazu folgendes Beispiel näher an:
"Die Katze ist weiß"
Gemeinsam mit seinem englischen Äquivalent "The cat is white" ist das Segment schon so im Translation Memory vorhanden:
Wenn dieser Satz nun in einem Ihrer Übersetzungsprojekte wieder vorkommt, spielt das Translation Memory System automatisch die Übersetzung aus – sofern die Segmentierung korrekt ist.
Das lässt sich gut mit folgendem Beispiel verdeutlichen:

In Segment 3 erhalten wir ein 100%-Match aus dem Translation Memory, da das Segment genauso im TM vorhanden ist. Das Translation Memory System befüllt das Segment also automatisch mit dem englischen Äquivalent "The cat is white".
In Segment 1 und 2 sieht es aber etwas anders aus. Denn die Segmente 1 und 2 bilden eigentlich einen gemeinsamen Satz, das System hat sie aber nicht korrekt ausgelesen und getrennt. Das Translation Memory System erkennt folglich nicht, dass der Satz eigentlich schon vorhanden ist und zeigt aufgrund der zu geringen Ähnlichkeit kein Match an.
Die richtige Segmentierung spielt also eine wichtige Rolle, damit die Übersetzenden auch Zugang zu den Übersetzungen im Translation Memory erhalten. Daher legen wir als Projektmanagement-Team auch viel Wert darauf, Sie auf nicht gut aufgeteilte Segmente aufmerksam zu machen und diese schon vor der Übersetzung bestmöglich abzufangen.
Unser Tipp: In Word-Dokumenten lässt sich leicht überprüfen, ob Sätze zu lang sind oder falsch getrennt werden. Denn das Einblenden der Absatzmarkierungen (Hard-Return) und der manuellen Zeilenumbrüche (Soft-Return) ermöglicht es, überflüssige Absätze schnell zu finden und bei Bedarf zu entfernen.
Fuzzy Matches in der Praxis
Wenn die Segmente jedoch eine höhere Ähnlichkeit als in dem Beispiel oben aufweisen, zeigt das Translation Memory System unterschiedliche Fuzzy Matchwerte an:
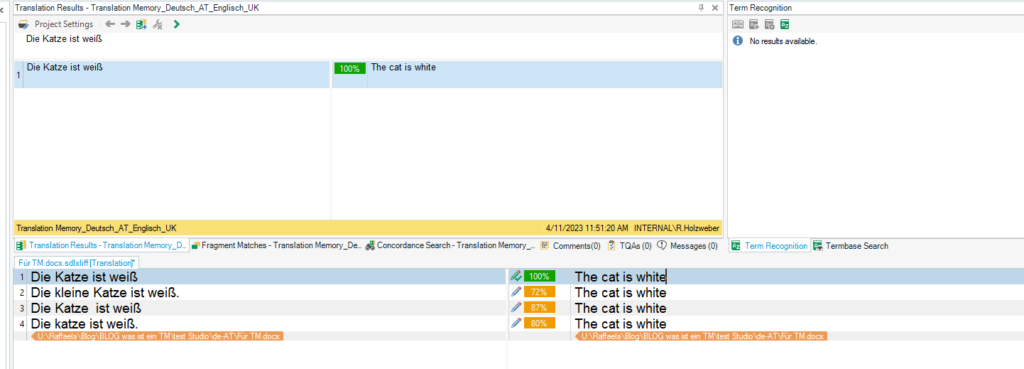
Sehen wir uns die Matchwerte nun gemeinsam an.
Im ersten Segment wird der Satz genauso verwendet, wie er auch im Translation Memory vorhanden ist. Daher wird dieses Segment auch mit einem 100%-Treffer markiert. Auch Segment 3 ist sehr ähnlich, hat jedoch zwischen "Katze" und "ist" ein doppeltes Leerzeichen. Das bedeutet, dass es sich aufgrund der unterschiedlichen Formatierung nicht mehr um ein 100%-Match handeln kann, sondern um ein Fuzzy Match, in diesem Fall von 87%.
In Segment 2 sind sowohl das Wort "kleine" als auch der Punkt am Satzende hinzugekommen. Daher haben wir hier ebenfalls ein Fuzzy Match (Matchwert 72%). Das Gleiche gilt auch für Segment 4, in dem es neben der Ergänzung des Punktes auch eine Änderung in der Schreibweise von "katze" gab (kleines "k"). Daraus resultiert auch hier ein Fuzzy Match (80%) und kein 100%-Match.
Wenn die Übersetzenden die Segmente angepasst und die Übersetzung abgeschlossen haben, spielen wir die Übersetzung direkt in Ihr Translation Memory ein. Damit werden die Fuzzy Matches aus dem Beispiel oben zu 100%-Matches. Denn das nächste Mal, wenn diese Segmente in einer Ihrer Übersetzungen vorkommen, sind sie schon genauso im Translation Memory vorhanden.
Konkordanzsuche
Wenn das Translation Memory System in einem Segment keinen Treffer anzeigt, können die Übersetzenden mithilfe der sogenannten Konkordanzsuche das Translation Memory auch aktiv nach bestimmten Termen durchsuchen:

Tippen die Übersetzenden beispielsweise den Term "Katze" ein, zeigt das Translation Memory alle Segmente an, in denen dieses Konzept vorkommt. Die Übersetzenden können somit auf bereits bestehende Übersetzungen zugreifen und auf die korrekte Übersetzung schließen.
Diese Funktion ist z.B. auch dann nützlich, wenn Sie die Dateien auf mehrere Teile über einen längeren Zeitraum verteilt schicken. Die Konkordanzsuche hilft dann schnell dabei, sich die korrekte Terminologie wieder in Erinnerung zu rufen. Wenn die Übersetzenden auch mithilfe der Konkordanzsuche kein Match finden, wählen sie die Übersetzung, die in dem gegebenen Kontext am idiomatischsten klingt.
Neben den Translation Memorys steht den Übersetzenden auch häufig eine Termdatenbank zur Verfügung, in der die wichtigsten Termini mehrsprachig erfasst sind. Diese stellt eine Art Glossar dar, das die Übersetzenden zusätzlich zum TM und häufig auch vorrangig als Quelle für den Einsatz der korrekten Terminologie nutzen.
3 Tipps für ein gut gepflegtes Translation Memory
Zu guter Letzt wollen wir Ihnen natürlich auch unsere 3 wichtigsten Tipps zum Thema Translation Memory nicht vorenthalten:
1. Das Translation Memory stetig pflegen und erweitern
Damit die Übersetzenden Ihr Translation Memory gut als Referenz nutzen können, ist eine gute Pflege entscheidend. Wir als Projektmanager:innen sorgen dafür, dass alle neuen Übersetzungen in Ihr Translation Memory gelangen und den Übersetzenden zur Verfügung gestellt werden.
Beim Einspielen der Übersetzungen achten wir auch darauf, dass keine Duplikate entstehen, sondern dass das Translation Memory System idente Segmente direkt überschreibt. Nach jeder Übersetzung vergrößert sich also die Anzahl an neuen Units im Translation Memory, was gleichzeitig auch die Wahrscheinlichkeit für Treffer in zukünftigen Übersetzungen erhöht.
2. Allen Übersetzenden Zugang ermöglichen
Da die Auslastung der Stammübersetzenden stark variieren kann, ist es manchmal notwendig, Übersetzungen mit Ihrer Zustimmung an andere Übersetzungsteams auszulagern. Damit die anderen Teams ebenfalls konsistent zu bestehenden Texten und qualitativ hochwertig übersetzen können, ermöglichen wir ihnen Zugang zu Ihren Translation Memorys. Das erleichtert ihnen die Auswahl der passenden Terminologie und das Translation Memory stellt eine wichtige Referenzquelle in ihrem Übersetzungsprozess dar. So können wir sicherstellen, dass auch die Übersetzungen der Alternativteams Ihren Vorstellungen entsprechen.
3. Ein Translation Memory ist nur so gut wie sein Inhalt
Die goldene Regel für Translation Memorys lautet: Ein Translation Memory ist nur so gut wie sein Inhalt. Wichtig dabei ist, dass die zielsprachlichen Segmente den Ausgangstext widerspiegeln. Manchmal kommt es vor, dass sich Segmente im Zuge des Reviewprozesses ändern und Informationen ergänzt werden, die eigentlich nicht im Ausgangstext stehen.
Dadurch können leicht "falsche" Übersetzungen ins Translation Memory gelangen, die das System das nächste Mal als 100%-Matches ausspielt. Für die Übersetzenden entsteht dann neben einem zeitlichen auch ein finanzieller Zusatzaufwand, um diese Segmente wieder an den Ausgangstext anzupassen. Daher achten wir im Projektmanagement-Team auch immer darauf, dass die Segmente möglichst sauber in das Translation Memory gelangen.
Fazit
Zusammenfassend lässt sich also sagen, dass das Translation Memory den Übersetzenden als eine sehr vielseitige Referenz dient. Neben den ausgespielten Matches in gut segmentierten Texten ist auch die Konkordanzssuche ein wichtiges Mittel, um Antworten auf terminologische Fragen zu erhalten. Mit einem gepflegten Translation Memory steht einer guten Übersetzung also nichts mehr im Wege.
Möchten Sie noch mehr zum Thema Translation Memorys erfahren? Kontaktieren Sie uns!
